
一直以來都有發現 Blog 的風格有點小問題
但都懶得去好好地找出問題
這次終於下定決定修好它
起源其實是我的上一篇文被嘴了 QAQ

整理下來大概有三個問題
- 大小標的 margin
- 英文前後也空一格
- 第二行縮了四分之一字元
1. 大小標的 margin
這應該是三個問題中最簡單的
但我有點懶得動 CSS ,所以就先不修了 xD
2. 英文前後也空一格
剛好最近看到了中文文案排版指北
才發現原來
「有研究顯示,打字的時候不喜歡在中文和英文之間加空格的人,感情路都走得很辛苦,有七成的比例會在 34 歲的時候跟自己不愛的人結婚,而其餘三成的人最後只能把遺產留給自己的貓。畢竟愛情跟書寫都需要適時地留白。與大家共勉之。」
——vinta/paranoid-auto-spacing
總之,這也不是特別難處理的問題
只要透過 add-space-between-latin-and-cjk 再加上 os.walk() 就能解決了
不過還是會遇到一些不該加空格的地方,也被加空格了
但也只要用 git diff 再確認一下哪裡有被 script 修改過就可以了
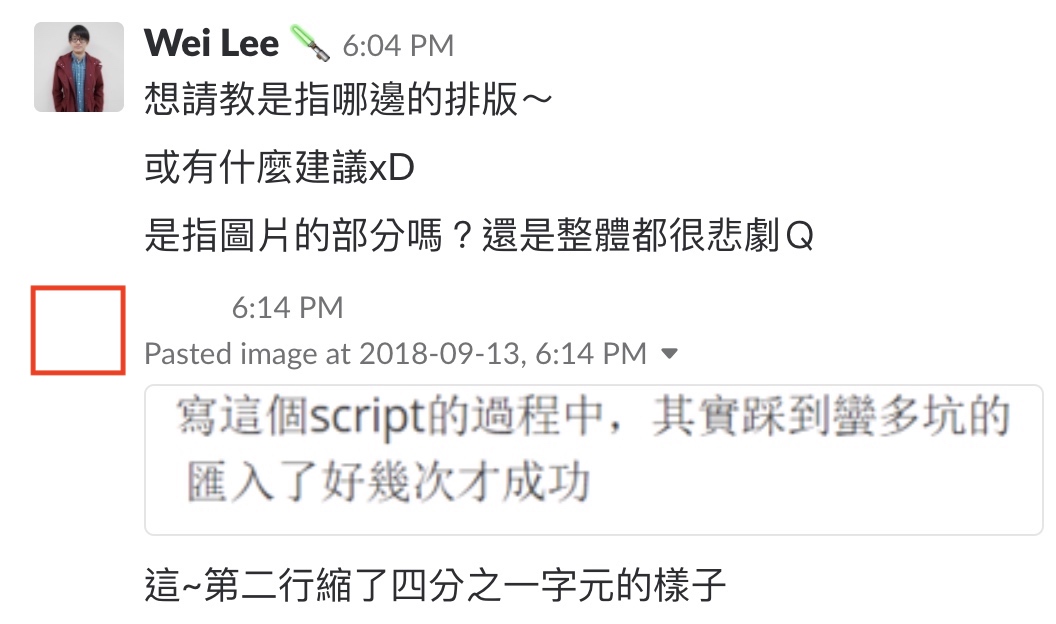
3. 第二行縮了四分之一字元
這個問題就比較頭痛了
因為我在模板找到這段的內容是
{{ article.content }}
也就是説這個多的空白是 pelican (我用的 static blog generator) 所產生的
我沒有辦法透過單純的修改 HTML, CSS 來修正這個問題
必須要找到 pelican 是從哪產生出這個空白的
於是就開始我的 trace pelican 的之旅
接下來,就是一連串的 trace 過程
不想看可以透過傳送門直接跳到解法
pelican/readers.py (first try)
要找到 Markdown 是在哪被 parse 並產生內容的並不困難
(pelican/readers.py 的 334行)
透過一些測試,發現這段的行為是因為有了多的 \n 造成了多的空白
第一個猜想是某些情況下的 \n 沒有成功的被移除掉
所以只要加一行 content.replace('\n', '') 確保全部的 \n 都被移除,應該就可以了
一開始問題也真的解決了
直到我用到 markdown中的 ``` 語法才又出現問題
在整個 code block 中的 code 全部都黏在一起沒有斷行
看來這個做法是行不通...
只好認命的從我平常產生文章的指令一步一步追回去
trace 的過程還有踩到一個雷是「pip 裝的 pelican 並不是 master 上的版本」
所以我還必須要切到 3.7.1版 才能開始解決我遇到的問題
setup.py
平常我都是透過 pelican -r -o output -s pelicanconf.py這個指令來產生文章
所以第一步就是要從 setup.py 找出 pelican 這個指令是哪裡來的
...
"pelican = pelican:main",
...
pelican/init.py
既然在 pelican 這個 package 中沒有 main.py
那 Python 還能找到 main 就只剩下 __init__.py
扣除掉一些 parse 指令參數的程式碼
接下來最像是產生文章的程式碼就是147行 的 run
for p in generators:
if hasattr(p, "generate_context"):
p.generate_context()
下一步就是要從 generators 找出 generate_context 這個函式
from pelican.generators import (
ArticlesGenerator,
PagesGenerator,
SourceFileGenerator,
StaticGenerator,
TemplatePagesGenerator,
)
pelican/generators.py
generators中看起來最有關的就是 ArticlesGenerator
這個 class 也找到了 generate_context
try:
article_or_draft = self.readers.read_file(
base_path=self.path,
path=f,
content_class=Article,
context=self.context,
preread_signal=signals.article_generator_preread,
preread_sender=self,
context_signal=signals.article_generator_context,
context_sender=self,
)
except Exception as e:
...
這裡找到的是文章被產生的地方
只要能在找到文章中的內容是在哪產生,應該就能解決我的問題
所以下一步就是要再去找到 Readers
pelican/reader.py
Readers 在這個檔案的486行
接著 trace 這個 class 到526行就真的是文章內容第一次被產生的地方
到目前為止,文章的內容還是沒有多餘的空白
所以順利的話只要從這繼續 trace 下去就能找出問題
content, reader_metadata = self.get_cached_data(path, (None, None))
if content is None:
content, reader_metadata = reader.read(path)
self.cache_data(path, (content, reader_metadata))
最後發現問題是出在 555行
if content:
content = typogrify_wrapper(content)
只要不對 content 做 typogrify_wrapper就不會產生多餘的空白
typogrify
typogrify 是 pelicanconf.py (pelican 的設定檔) 中的一個設定
TYPOGRIFY = False
只要關掉 typogrify 就不會再產生出多餘的空白
typogrify 看來是某種加強 HTML 的工具
我試過要把 <br> 跟   加入 TYPOGRIFY_IGNORE_TAGS
不過看來還是沒辦法解決
最後只好把 typogrify 整個關掉了
後記
其實這也只是個無傷大雅的小問題
但真的是花了我不少時間才找到真正的問題所在
前幾次都能透過 trace 原始碼,找到 library 的一些小問題
也丟了幾個 Pull Request
不過看來這次沒能再多貢獻什麼
雖然好像有找到可能從 typogrify 解決掉這個 issue的方式
但要再把它加入 pelican 變成一種 config 還是有些麻煩 xD