
We've versioned our data in the previous post. This article will demonstrate how we could define a data pipeline and version it through DVC.
Pipeline versioning
We'll continue using dvc_example. You can checkout to tag v3-remove-2-rows to follow along.
Split training logic into different stages
In the original design, we use pipenv run python digit_recognizer/digit_recognizer.py to run the whole training process. We'll split them into process-data, train, and report stages.
def main():
...
if args.command == "process-data":
X, y = load_data("data/digit_data.csv", "data/digit_target.csv")
X_train, X_test, y_train, y_test = process_data(X, y)
export_processed_data((X_train, y_train), "output/training_data.pkl")
export_processed_data((X_test, y_test), "output/testing_data.pkl")
elif args.command == "train":
X_train, y_train = load_processed_data("output/training_data.pkl")
model = train_model(X_train, y_train)
export_model(model, "output/model.pkl")
elif args.command == "report":
X_test, y_test = load_processed_data("output/testing_data.pkl")
model = load_model("output/model.pkl")
predicted_y = model.predict(X_test)
output_test_data_results(y_test, predicted_y)
output_metrics(y_test, predicted_y)
You can view the complete code change on v3-remove-2-rows...v4-split-pipeline-logic.
After these changes, we'll use the following 3 commands to run the pipeline.
pipenv run python digit_recognizer/digit_recognizer.py process-data
pipenv run python digit_recognizer/digit_recognizer.py train
pipenv run python digit_recognizer/digit_recognizer.py report
Add the first stage in our pipeline to DVC
We add stages through dvc run command. Let's add our first stage process-data.
# add process-data stage
$ pipenv run dvc run --name process-data \
-d digit_recognizer/digit_recognizer.py \
-d data/digit_data.csv \
-d data/digit_target.csv \
-o output/training_data.pkl \
-o output/testing_data.pkl \
"pipenv run python digit_recognizer/digit_recognizer.py process-data"
Running stage 'process-data':
> pipenv run python digit_recognizer/digit_recognizer.py process-data
Creating 'dvc.yaml'
Adding stage 'process-data' in 'dvc.yaml'
Generating lock file 'dvc.lock'
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.yaml output/.gitignore dvc.lock
Next, we add these DVC files into git to track.
# add DVC configuration to git and commit
$ git add dvc.yaml dvc.lock output/.gitignore
$ pipenv run cz commit
See what's composed of this command
--name: the name of this stage- It must be unique throughout the project.
-d: the dependencies of this stage- All the files related to running this stage should be counted as dependencies.
- DVC won't these dependency files into it storage but only store the hashes of them.
- In this example, we need
digit_recognizer/digit_recognizer.pyto loaddata/digit_data.csvanddata/digit_target.csvto process the data. Thus, these 3 files are added as dependencies.
-o: the output files of this stage- DVC stores these files in its storage. If you want to track it through git or simply don't want to track it, you can use
-Oinstead.
- DVC stores these files in its storage. If you want to track it through git or simply don't want to track it, you can use
dvc run runs the stage right after adding it. If you don't want DVC to run it, you can add --no-exec flag or dvc stage add with the same arguments
After adding a stage, DVC updates dvc.yaml, output/.gitignore and dvc.lock
dvc.yaml: the definition of stages
stages:
process-data:
cmd: pipenv run python digit_recognizer/digit_recognizer.py process-data
deps:
- data/digit_data.csv
- data/digit_target.csv
- digit_recognizer/digit_recognizer.py
outs:
- output/testing_data.pkl
- output/training_data.pkl
DVC transforms what we defined in dvc run to a human-readable format and store it. But if you already know how to define the stage, you can edit dvc.yaml directly. In addition, there're advanced techniques like Templating and foreach stages that can help us define complicated stages.
dvc.lock: the hashes of dependencies and outputs
schema: '2.0'
stages:
process-data:
cmd: pipenv run python digit_recognizer/digit_recognizer.py process-data
deps:
- path: data/digit_data.csv
md5: 942481fce846fb9750b7b8023c80a5ef
size: 490582
- path: data/digit_target.csv
md5: 2a6cfa13365ac9b3af5146133aca6789
size: 3590
- path: digit_recognizer/digit_recognizer.py
md5: 65ecf27479538a74ade42462b1566db1
size: 3629
outs:
- path: output/testing_data.pkl
md5: 78be1761d227f71b1a8f858fed766982
size: 529016
- path: output/training_data.pkl
md5: f95e8f978a05395ba23479ff60eda076
size: 528427
DVC uses these hashes to know whether there's any modification on our stages. Therefore, we only add deterministic files. Randomness might make this lock file meaningless. Take a look at the "Avoiding unexpected behavior" in dvc run - Description could save your time debugging unexpected failure.
output/.gitignore: Add files that DVC should track to gitignore
Define the whole pipeline
With similar command, we can add train and report stages to our pipeline.
# add train stage
pipenv run dvc run --name train \
-d digit_recognizer/digit_recognizer.py \
-d output/training_data.pkl \
-o output/model.pkl \
"pipenv run python digit_recognizer/digit_recognizer.py train"
# add report stage
pipenv run dvc run --name report \
-d digit_recognizer/digit_recognizer.py \
-d output/testing_data.pkl \
-d output/model.pkl \
-o output/metrics.json \
-o output/test_data_results.csv \
"pipenv run python digit_recognizer/digit_recognizer.py report"
# add DVC configuration to git and commit
git add dvc.yaml dvc.lock model/.gitignore
pipenv run cz commit
Similar to our previous step, DVC updates dvc.yaml, dvc.lock and output/.gitignore.
$ cat dvc.yaml
...
train:
cmd: pipenv run python digit_recognizer/digit_recognizer.py train
deps:
- digit_recognizer/digit_recognizer.py
- output/training_data.pkl
outs:
- output/model.pkl
report:
cmd: pipenv run python digit_recognizer/digit_recognizer.py report
deps:
- digit_recognizer/digit_recognizer.py
- output/model.pkl
- output/testing_data.pkl
outs:
- output/metrics.json
- output/test_data_results.csv
We can visualize the pipeline through dvc dag
$ pipenv run dvc dag
+----------+
| data.dvc |
+----------+
*
*
*
+--------------+
| process-data |
+--------------+
** **
** *
* **
+-------+ *
| train | **
+-------+ *
** **
** **
* *
+--------+
| report |
+--------+
If you pay attention to each parameter passes to dvc run, you might have noticed that train stage depends on the output output/training_data.pkl from process-data stage. This is how DVC decides the order of each stage in our pipeline.
Run the pipeline
Contradict to its naming, dvc run is only used for defining the stage and run it for the first time. dvc repro (reproduce) is what we use to run the pipeline,
$ pipenv run dvc repro
'data.dvc' didn't change, skipping
Stage 'train' didn't change, skipping
Data and pipelines are up to date.
Because we've not yet made any changes since we define our pipeline, DVC won't waste time and resources to generate results it has already known. However, you can add a -f flag to force DVC to rerun the pipeline.
Next, we'll change gamma to 0.01 to see how dvc repro works.
def train_model(X_train, y_train, params):
...
clf = svm.SVC(gamma=0.01)
...
Because our dependency digit_recognizer/digit_recognizer.py has been modified, DVC expects the result might be different. Therefore, we can now run dvc repro.
$ pipenv run dvc repro
'data.dvc' didn't change, skipping
Running stage 'process-data':
> pipenv run python digit_recognizer/digit_recognizer.py process-data
Updating lock file 'dvc.lock'
Running stage 'train':
> pipenv run python digit_recognizer/digit_recognizer.py train
Updating lock file 'dvc.lock'
Running stage 'report':
> pipenv run python digit_recognizer/digit_recognizer.py report
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
Use `dvc push` to send your updates to remote storage.
By running git diff, you'll find out that the hashes of digit_recognizer/digit_recognizer.py, output/model.pkl, output/metrics.json, output/test_data_results.csv inside dvc.lock has been changed.
Track parameters
In the previous section, even though we change only the parameter related to the train stage, DVC still reruns the whole pipeline. To make DVC runs only the stages affect by the changed parameters, we can refactor our code to load parameters from a separate file params.yaml.
def main():
params = load_params("params.yaml")
X, y = load_data("data/digit_data.csv", "data/digit_target.csv")
X_train, X_test, y_train, y_test = process_data(X, y, params["process_data"])
model = train_model(X_train, y_train, params["train"])
export_model(model)
...
This is how params.yaml looks like.
process_data:
test_size: 0.5
shuffle: false
train:
gamma: 0.01
Full code changes can be found on v5-parameters-in-separate-file.
To add parameters to a stage, we'll need to run the previous dvc run command again with -f and -p flag.
-f: overwrite the stage with the same name-p: parameters- Use "," to separate parameters
# Add parameters process_data.test_size and process_data.shuffle to process-data stage
pipenv run dvc run -f --name process-data \
-d digit_recognizer/digit_recognizer.py \
-d data/digit_data.csv \
-d data/digit_target.csv \
-o output/training_data.pkl \
-o output/testing_data.pkl \
-p process_data.test_size,process_data.shuffle \
"pipenv run python digit_recognizer/digit_recognizer.py process-data"
# Add parameters train.gamma to train stage
pipenv run dvc run -f --name train \
-d digit_recognizer/digit_recognizer.py \
-d output/training_data.pkl \
-o output/model.pkl \
-p train.gamma \
"pipenv run python digit_recognizer/digit_recognizer.py train"
# add DVC configuration to git and commit
git add dvc.yaml dvc.lock model/.gitignore
pipenv run cz commit
DVC adds params key to both process-data and train stages in dvc.yaml.
stages:
process-data:
......
params:
- process_data.shuffle
- process_data.test_size
train:
......
params:
- train.gamma
params.yaml is the default parameter file name, but DVC also supports YAML, JSON, TOML, and Python files. We only need to add the file name as an additional layer to params to use it. e.g.,
# this is an example of using different parameter file name
# we don't need to make changes to our code
train:
......
params:
- params.json
- train.gamma
Let's change gamma to 0.1. We can check this change through dvc params diff. By providing git reference, we can even see parameters difference between different git commits. (e.g., dvc params diff HEAD~1)
$ pipenv run dvc params diff
Path Param Old New
params.yaml train.gamma 0.01 0.1
If we run dvc repro now, DVC reruns only train and report stages. train stage is affected by train.gamma change. Due to this change, the output file from the train stage has been updated. Thus, DVC reruns report stages as well.
$ pipenv run dvc repro
'data.dvc' didn't change, skipping
Stage 'process-data' didn't change, skipping
Running stage 'train':
> pipenv run python digit_recognizer/digit_recognizer.py train
Updating lock file 'dvc.lock'
Running stage 'report':
> pipenv run python digit_recognizer/digit_recognizer.py report
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
Use `dvc push` to send your updates to remote storage.
# reset gamma back to 0.01
$ git checkout dvc.lock params.yaml
We're not going to store this parameter change. Run git checkout out params.yaml dvc.lock to restore the previous state.
Track metrics
We now know how to track parameters. Next, we'll see how changing these parameters affect the performance of our models. You may have already noticed that we've outputted a output/metrics.json file. Although we could track it as the output file, DVC has better support for metrics files.
Like adding parameters, we add -m flag for DVC to recognize the output as metrics. Instead of using -M as the official tutorial did, I use -m because I prefer tracking metrics through DVC remote storage instead of saving it to git as part of our source code.
# Add output/metrics.json as metrics to report stage
$ pipenv run dvc run -f --name report \
-d digit_recognizer/digit_recognizer.py \
-d output/testing_data.pkl \
-d output/model.pkl \
-o output/test_data_results.csv \
-m output/metrics.json \
"pipenv run python digit_recognizer/digit_recognizer.py report"
# add DVC configuration to git and commit
$ git add dvc.yaml dvc.lock model/.gitignore
$ pipenv run cz commit
# metrics have been added to the report stage as expected
$ cat dvc.yaml
...
report:
......
metrics:
- metrics.json:
Use dvc metrics show to see how well our model performs
Note that values are not calculated through DVC. DVC only provides a way to display values in file organized as tree hierarchies and compare them throughout different git commits.
$ pipenv run dvc metrics show
Path accuracy_score weighted_f1_score weighted_precision weighted_recall
output/metrics.json 0.69265 0.74567 0.91941 0.69265
Change gamma to 0.1 again and use dvc metrics diff to see if model performance is improved after this change.
# reruns the pipeline with new parameters
$ pipenv run dvc repro
# check metrics differences between unstaged and HEAD
$ pipenv run dvc metrics diff
Path Metric Old New Change
output/metrics.json accuracy_score 0.69265 0.10134 -0.59131
output/metrics.json weighted_f1_score 0.74567 0.01865 -0.72702
output/metrics.json weighted_precision 0.91941 0.01027 -0.90914
output/metrics.json weighted_recall 0.69265 0.10134 -0.59131
# reset gamma back to 0.01
$ git checkout dvc.lock params.yaml
We don't need this change either. Reset gamma back to 0.01 through git checkout
plotting
There's only one left output output/test_data_results.csv that has not yet been used. This file stores the ground truth and the predicted result from our model. We're going to use it to see how DVC plots our data. Before plotting, let's change gamma to 0.001 first and run dvc repro. Otherwise, the output plot will look a bit odd due to the low model performance.
$ cat output/test_data_results.csv
actual,predicted
4.0,4.0
8.0,8.0
......
Add --plots flag and specify output/test_data_results.csv as the file to plot
# add output/test_data_results.csv as the file to plot to report stage
$ pipenv run dvc run -f --name report \
-d digit_recognizer/digit_recognizer.py \
-d output/testing_data.pkl \
-d output/model.pkl \
-o output/test_data_results.csv \
-m output/metrics.json \
--plots output/test_data_results.csv \
"pipenv run python digit_recognizer/digit_recognizer.py report"
# plots have been added to dvc.yaml
$ cat dvc.yaml
......
plots:
- output/test_data_results.csv
DVC generates plots through Vega, a declarative grammar that can define interactive graph in JSON format. It supports linear plot, scatter plot, and confusion matrix by default. These templates are stored in .dvc/plots. We can also define our plots. (Read
dvc plots - Custom templates to find out more)
In the following example, we'll plot a confusion matrix through dvc plots show.
$ pipenv run dvc plots show output/test_data_results.csv --template confusion -x actual -y predicted --out confusion_matrix.html
file:///....../confusion_matrix.html
--template: name of the plot template-x: field name of the data for the X-axis-y: field name of the data for the y axis--out: output file name
The following is a screenshot of the generated plot.
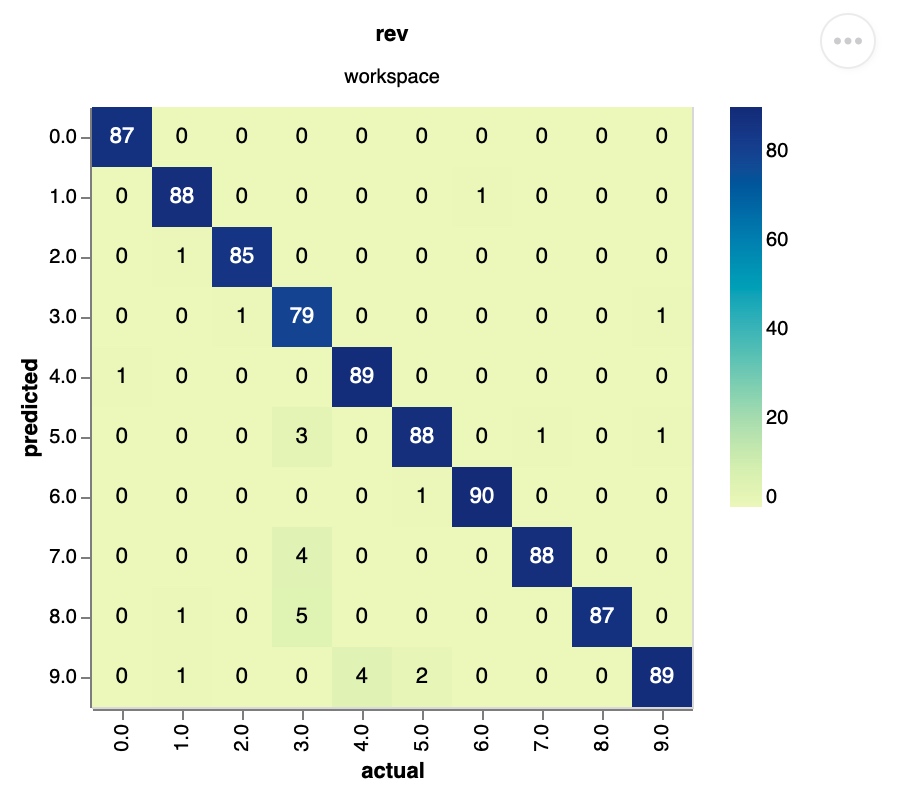
As of now, DVC does not track our plot (i.e. confusion-matrix.jpg) but only our data to plot (i.e., output/test_data_results.csv). Let's add plot as the final stage of our pipeline.
# Add stage plot
pipenv run dvc run -f --name plot \
-d output/test_data_results.csv \
-o confusion_matrix.html \
"pipenv run dvc plots show output/test_data_results.csv --template confusion -x actual -y predicted --out confusion_matrix.html"
Conclusion
In this post, we create a data pipeline that process data, train the model, generate the report and visualize it.
$ pipenv run dvc dag
+----------+
| data.dvc |
+----------+
*
*
*
+--------------+
| process-data |
+--------------+
* *
** *
* **
+-------+ *
| train | **
+-------+ *
* *
** **
* *
+--------+
| report |
+--------+
*
*
*
+------+
| plot |
+------+
We also see how to use DVC to track each component and provide an easy way to run the pipeline. In the following article, we will discuss how to run experiments with different parameters and compare the results in an even more convenient way.
One more thing: When should we save files to DVC instead of git?
Short answer: It depends.
When defining pipeline we can decide whether to save our outputs (-o / -O), metrics (-m / -M) and plots (--plots / --plots-no-cache) to DVC storage. DVC document suggests not storing metrics and plots to DVC as they are typically small enough for git to track. But I'd prefer storing only thing relates to our logic to git. That's why I use -m and --plots in the examples. If you don't want to track these, you could just pass -O, -M, or --plots-no-cache and add them to both .gitignore and .dvcignore.