
Main Purpose: To see how linguistic features correlate with each personality trait.
Use Twitter to predict MBIT personality.
Problem of Past Researches
- Language on social media has richer content that makes the typical linguistic analysis tool perform poorly (e.g. iono → I don't know)
- Gain personality information is costly (e.g. Big Five Questionnaire)
MBTI
Instead of commonly used big five theory, MBTI is used in this paper.
There are 4 types of personality trait
i.e.
- Introversion(I) / Extroversion(E)
- Intuition(N) / Sensing(S)
- Feeling(F) / Thinking(T)
- Perception(P) / Judging(J)
Personality can be expressed as a code with 4 letters.
e.g. ENFJ, INTP
Data
- A Twitter dataset
- Around 90,000 users
- 120,000 personality-related tweets from 2006~2015 (out of 1.7 M tweets)
What is the so-called personliaty-related tweets?
- English Tweets that contain users' own MBIT code.
e.g."I'm an ENFJ"is qualified"My friend is an ISFJ"is not qualified
- Heuristic rules is used (e.g.
"I'm","I got","I have been a") - No classification method is used for ensuring the personality code is indeed the user's
Distribution
Personality distribution of this data is skewed.
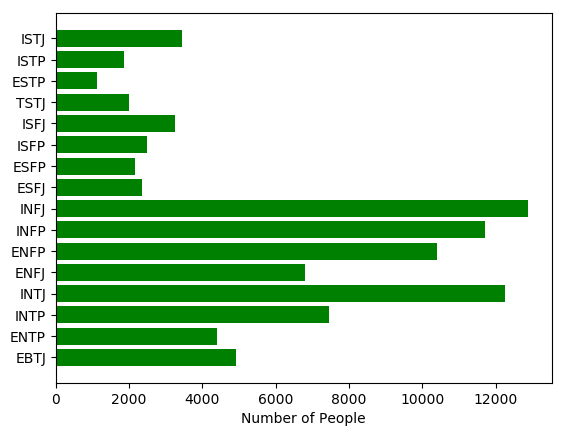
However, in the real word, the personality distribution might also be skewed.
Features
1. n-grams
- Most frequent 1,000 unigram, bigram, trigram words and phrases
- 1,000 dimensions vectors for unigram, bigram trigram for each user
2. Twitter Part-of-speech tags
Based on Part-of-Speech Tagging for Twitter: Annotation, Features, and Experiments
- 25 types with some Twitter-specific tag.
e.g.- hashtag
- at-mention
- URL
- emoticon
3.word vectors
-
Word Vector Settings
- 2,334,564 words
- 500 dimension
-
Extracted Features
- Average word vectors
- Weighted average word vectors (weighted according to TF-IDF)
Prediction
Logistic Regression is used (Random Forest and SVM produced similar results)
Accuracy Measurement
Since the data is skewed, AUC is used.
Accuracy
- Indivisula Features
- Word Vector Only → (AUC=0.651)
- n-gram only → (AUC=0.607)
- POS only → (AUC=0.585)
- Combined Features
- All three features → (AUC=0.661)
- POS + n-gram → (AUC=0.616)
Insight
Among the results, word vector performs best which might illustrate that predictions based on social media and language would work.
During the POS conversion process, information is compressed into 25 tags and might lost some important one.
This might be the reason why it performs worse.